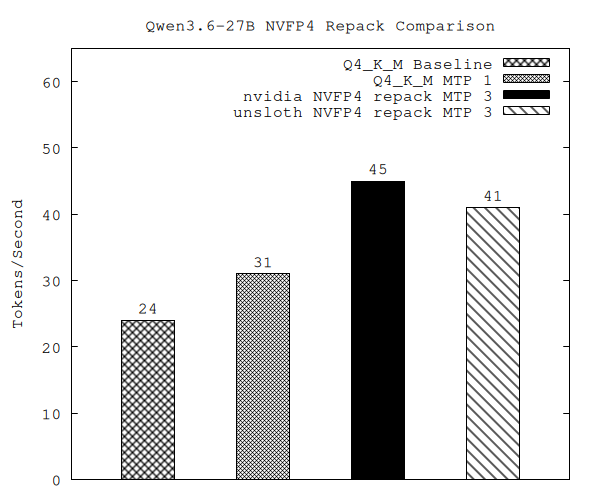
Qwen3.6-27B is arguably the best model you can fit on a 24 GB GPU today. But “fit” and “fast” are different problems and the most interesting quantization format for Blackwell hardware, NVFP4, doesn’t run on the tools most of us actually use locally. This is the story of how we got it running at nearly 2x our starting throughput, including a detour into patching llama.cpp’s conversion script to handle a checkpoint it flatly refused to load.
TL;DR: We repackaged the NVIDIA and unsloth NVFP4 checkpoints of Qwen3.6-27B into GGUF, so they run on llama.cpp’s native sm_120 FP4 tensor-core path. On an RTX 5090 Laptop (24 GB), combined with the model’s MTP head for speculative decoding, this took us from 24 tok/s (a popular Q4_K_M build) to 45 tok/s at 160K context. The NVIDIA checkpoint converts out of the box; the unsloth one needed a small patch to the convert script, which we describe in detail.
The ASUS ProArt P16 seems to have a bug in the power management that makes bluetooth connections stutter when the Nvidia GPU wakes up: #3878. This is quite annoying but you can work around it by enabling the respective devices permanently:
echo on | sudotee /sys/bus/pci/devices/0000:64:00.0/power/control echo on | sudotee /sys/bus/pci/devices/0000:64:00.1/power/control
Connecting a Keyboard With Pairing Key
Pop!_OS is currently lacking a way to pair device that require a passkey through the UI. However, you can use bluetoothctl to pair the device. In our example we use a Logitech MX Keys Mini keyboard. This specific device can be put into pairing mode by holding one of the three device selectors until it blinks rapidly.
Other devices may differ in this regard. Anyway, put it into pairing mode and open a terminal, then follow these steps:
# Open the bluetoothctl tool bluetoothctl
# Enable the controller to search for your device scan on # List all discovered devices, note the MAC address of your device devices
# To avoid problems, restart the correct agent agent off agent KeyboardOnly
# Now pair your device using the MAC address discovered before pair D5:44:64:5F:DC:EA
# Set a passkey [agent] Enter passkey (number in 0-999999): 123456 # Now repeat the passkey on the keyboard and your device should be connected
Large Language Models (LLMs), or AI, are widely adopted by now. Most of us use it daily for work, leisure and private matters. That also means that we share a lot of possibly sensitive information with the LLM. This can be problematic when using 3rd party services like ChatGPT, especially now that OpenAI has to retain all chat logs indefinitely. So how about running an LLM on your own hardware?
We previously measured two popular current-generation llama 3 and deepseek-r1. This time we follow up with Qwen3 and Gemma3, both released in the last months. We want to give you an idea which kind of model will run on what hardware and what kind of performance you can expect.
Test Setup
We test two of the currently popular LLM families, Qwen3 and Gemma3, in quantized and 16bit floating point (fp16) versions for their performance on consumer hardware. We run the models using ollama 0.9.2 and open-webui as frontend. We collect the measured response tokens after executing the following query:
I need a summary of the book “War and Peace¨. Please write at least 500 words.
For each test, the model fits into the memory of the graphics card (VRAM). Mobile devices are allowed to cool down before each test run.
For Qwen3, the thinking mode was left at default, which is “on”.
Tested Models
In this article we focus on two of the currently popular LLMs:
Qwen3, developed by Alibaba, is optimized for deployment on Alibaba Cloud infrastructure, leveraging GPUs and specialized AI accelerators. It excels in advanced conversational AI, content generation, multilingual interactions, and complex reasoning tasks. Typical applications include customer support automation, virtual assistants, translation, summarization, and sentiment analysis. Its scalable architecture ensures efficient integration into cloud-based business solutions, particularly within Alibaba’s ecosystem.
Gemma3, created by Google DeepMind, is designed for versatility and efficiency across diverse hardware platforms, including consumer-grade GPUs, CPUs, and edge devices. It effectively handles tasks such as text generation, summarization, conversational AI, and question-answering. Its lightweight, open-source architecture makes it ideal for resource-constrained environments, enabling applications like personal assistants, educational tools, and interactive chatbots. Gemma3’s open-source nature encourages customization, experimentation, and broad adoption in both research and industry contexts.
Model
Variant
Precision
VRAM Size
qwen3:0.6b
Q4_K_M
2.2GB
qwen3:4b
Q4_K_M
5.2GB
qwen3:8b
Q4_K_M
7.5GB
qwen3:14b
Q4_K_M
12GB
qwen3:32b
Q4_K_M
25GB
qwen3:0.6b
fp16
3GB
qwen3:1.7b
fp16
5.3GB
qwen3:4b
fp16
10GB
qwen3:8b
fp16
18GB
qwen3:14b
fp16
32GB
gemma3:1b
instruct
Q4_K_M
1.9GB
gemma3:4b
instruct
Q4_K_M
6GB
gemma3:12b
instruct
Q4_K_M
11GB
gemma3:27b
instruct
Q4_K_M
21GB
gemma3:1b
instruct, quantization aware
Q4_K_M
2.1GB
gemma3:4b
instruct, quantization aware
Q4_K_M
6.6GB
gemma3:12b
instruct, quantization aware
Q4_K_M
12GB
gemma3:27b
instruct, quantization aware
Q4_K_M
22GB
gemma3:1b
instruct
fp16
3.1GB
gemma3:4b
instruct
fp16
11GB
gemma3:12b
instruct
fp16
31GB
gemma3:27b
instruct
fp16
63GB
Table 1: tested llms
Table 1 shows the tested LLMs. Ollama uses quantized models by default. If you specify a more detailed tag you can choose different quantizations as well as the non-quantized floating point versions. We select Qwen3 and Gemma3 for their popularity and start with the smallest versions parameter-wise. We continuously choose higher parameter models until they would not fit into any of the test systems VRAM. The last column in the table shows the size of the model when loaded into VRAM as reported by ollama ps. We can already see here that not all models will fit into the VRAM of the test systems from Table 2.
The Typescript x AI organizers and speakers: Luca Becker, Carl Assmann, Luisa Peter, Lucas L. Treffenstädt, Benjamin Behringer, Alexander Opalic, Johannes Loher
Talk Abstract
Nearly every AI-enabled product in 2025 has a summarizing function. But they all use 3rd party software to get the summary. This raises major privacy concerns and is prohibitive for most of us in the community. We display a small React/Typescript app that will enable you to summarize even longer text on your local machine or anywhere and a Large Language Model of your choosing. We motivate the app and show it in a live demo with local and remote LLMs. We discuss different approaches to prompting and the quality of summaries on various LLMs. We show the implementation and dive into the most interesting parts of the code.
LLMs are huge, slow to run and require terrabytes of RAM on the newest graphics cards, right? Well, maybe not. In this article we compare the performance of two popular current LLMs: llama 3.x and deepseek-r1 on a variety of consumer hardware from Laptop GPUs to dual Nvidia 5090s. We test quantized and full precision models and show which one can fit into the memory of your graphics card. We also test against Apples M chip series and explore what can be achieved with older but cheaper server hardware.
Test Setup
We test two of the currently popular LLM families, llama 3 and deepseek-r1, in quantized and 16bit floating point (fp16) versions for their performance on consumer hardware. We run the models using ollama 0.6.5 and open-webui as frontend. We collect the measured response tokens after executing the following query:
I need a summary of the book “War and Peace¨. Please write at least 500 words.
For each test, the model fits into the memory of the graphics card (VRAM). Mobile devices are allowed to cool down before each test run.
Tested Models
In this article we focus on two of the currently popular LLMs:
Llama 3, developed by Meta, represents the latest evolution in open-source large language models, building upon its predecessors with enhanced capabilities, improved efficiency, and greater contextual understanding. It comes in various sizes, typically ranging from smaller, more efficient models suitable for edge computing and personal devices, to larger, more powerful variants designed for complex tasks and extensive data processing. Its versatility makes it ideal for applications such as chatbots, content generation, coding assistance, and research. For the AI community, Llama 3 signifies a significant step toward democratizing advanced AI technology, fostering innovation, and enabling broader access to sophisticated AI tools and research opportunities.
DeepSeek-R1, developed by DeepSeek AI, is a cutting-edge large language model designed specifically to excel in coding and technical tasks. It comes in multiple variants, including models optimized for general-purpose programming, debugging, and software development assistance, making it highly versatile for developers and tech professionals. Its primary uses include code generation, error detection, automated debugging, and providing detailed technical explanations. For the AI community, DeepSeek-R1 represents a significant advancement in specialized AI models, enhancing productivity and accuracy in software development, and contributing to the broader adoption of AI-driven coding solutions.
Model
Variant
Precision
VRAM Size
llama3.2:1b
instruct
Q8_0
2.7GB
llama3.2:3b
instruct
Q4_K_M
4GB
llama3.1:8b
instruct
Q4_K_M
6.9GB
llama3.3:70b
instruct
Q4_K_M
49GB
llama3.2:1b
instruct
fp16
3.9GB
llama3.2:3b
instruct
fp16
8.5GB
llama3.1:8b
instruct
fp16
17GB
deepseek-r1:7b
qwen distill
Q4_K_M
6GB
deepseek-r1:8b
llama distill
Q4_K_M
6.9GB
deepseek-r1:14b
qwen distill
Q4_K_M
11GB
deepseek-r1:32b
qwen distill
Q4_K_M
25GB
deepseek-r1:70b
qwen distill
Q4_K_M
49GB
deepseek-r1:1.5b
qwen distill
fp16
4.2GB
deepseek-r1:7b
qwen distill
fp16
16GB
deepseek-r1:14b
qwen distill
fp16
32GB
Table 1: tested llms
Table 1 shows the tested LLMs. Ollama uses quantized models by default. If you specify a more detailed tag you can choose different quantizations as well as the non-quantized floating point versions. We select llama 3.x and deepseek-r1 for their popularity and start with the smallest versions parameter-wise. We continuously choose higher parameter models until they would not fit into any of the test systems VRAM. The last column in the table shows the size of the model when loaded into VRAM as reported by ollama ps. We can already see here that not all models will fit into the VRAM of the test systems from Table 2.
In our earlier post “Will AI Kill The Blogosphere?” we discussed the impact of AI on content creation in the internet and how to react to this change. Now we want to find out what the AI itself thinks of the subject and our previous article. We created a rebuttal using the following prompt:
Read the given article and write a response. Evaluate the premise and conclusion in detail. Draw your own conclusion on the subject. Be honest and don´t hold back. Try to provide value for the reader.
The following the Grok 3’s answer. Enjoy!
Response to the Article: AI’s Impact on Content Creation and Knowledge Sharing
The article “The Impact of AI on Content Creation and Knowledge Sharing” explores how artificial intelligence is reshaping the landscape of content creation and the dissemination of knowledge. Below, I’ll evaluate the article’s premise and conclusion in detail, offer my own perspective, and provide actionable insights for readers navigating this evolving terrain. Let’s dive in.
There is a whole business segment out there of people making money writing blogs. Either they earn money directly from ads, affiliate links, subscriptions or donations, or they grow the blog to a certain viewership and then sell it to someone who needs a platform to promote their product. There are marketplaces for this like Flippa and Motion Invest, to name two, and Youtube channels like Income School to teach you how to do it. And albeit the multiples for selling such a blog are relatively low at around 2-3, if you can grow the blog fast enough and maybe do more than one at a time, it’s still a profitable business.
At the same time, there are tens of thousands of users on Stack Overflow, answering the millions of new questions per year for free. These people are not getting paid but receive a different kind of reward: recognition. Apparently, a strong enough motivator.
But with the advent of AI and their liberal use of copyrighted material, or just plain piracy, both kinds of incentives might be threatened: If on one hand AI scrapes your content so people don´t need to visit your page to create clicks or recognize your name, and on the other hand the AI might create the kind of content you provide directly without needing your input, then why put in the time and effort to create content, especially when you depend on the ability to sell it for money? Consequently, there are various signs that content creation on Stackoverflow is dropping: 1, 2, 3, and also Blog sales are contracting.
So you want to follow the hype and generate some images with Stablility AI`s shiny new Stable Diffusion 3.5 model (SD 3.5). You find the model on Hugging Face, and hey, there is a code example to try it out. And it works!?
Absolutely not!
Inconveniently there are a lot more steps to take and considerations to make before your python script will generate an AI image, especially on consumer hardware with little VRAM. This article shows how to really do it, even on a laptop GPU with only 6GB of VRAM. As such it is an adapted collection of other material available on the web.
Docker Desktop just got more pricey again. Let’s explore some ways to replace at least part of its functionality like running docker containers and doing networking. This guide will be for the Windows operating system, as it is the one where users will most likely use Docker Desktop.
We will use the Hyper-V virtualization solution already present on Windows and show how to integrate your Docker Desktop replacement into your environment.
I bought me a Tesla Model 3 in August of 2023. I did it mostly because I was bored but also to take advantage of the government subsidies that were available at that time. Hey, if the government wants to spend my taxes, they should spend it on me. Right of the bat: The car is good. It has its flaws like most cars but also a lot of nice features to make up for it. Some quirks also arise from the new EV technology and neither Tesla nor the car itself can do anything to fix it. But there are strong opinions on EVs from both supporters or opposers of the technology. Here I want to share my observations on some of the most common prejudices and also share some learnings of my own.